论文:Dilated Residual Networks CVPR2017
代码:https://github.com/fyu/drn pytorch
现在用于分类的大多数卷积神经网络,都是将图片分辨率降低了32倍的。在输入固定的情况下(分类一般都是224×224),最后的输出是7×7的feature map,选择这个倍数,在减少模型的参数量和计算量的同时保证最后的feature map不至于丢失太多信息。这对于分类问题来说是比较合理的,但是对于分割或者定位或者检测来说,毕竟属于像素级别的分类任务,如果还是选择32的总步长,势必会丢掉一些信息。但是如果选择小的步长,又会使感受野变小。所以现在有些文章会采用 up-convolutions, skip connections, and posthoc dilation等操作在降低步长的同时,维持感受野。
这篇文章使用了 Dilated Convolution ,也就是空洞卷积,或者膨胀卷积,或者带孔卷积。空洞卷积的使用使得网络可以在减少步长的情况下,保持感受野不变。关于空洞卷积的原理见 [参考资料 1],这里不再叙述。
Dilated Convolution 与ResNet的结合,所以本文叫做Dilated Residual NetWorks,简称DRN。
1 DRN
ResNet的总步长为32,由于直接降低步长会影响感受野,所以作者使用 Dilated Convolution 来改进ResNet。
如下图,DRN与ResNet的对比。
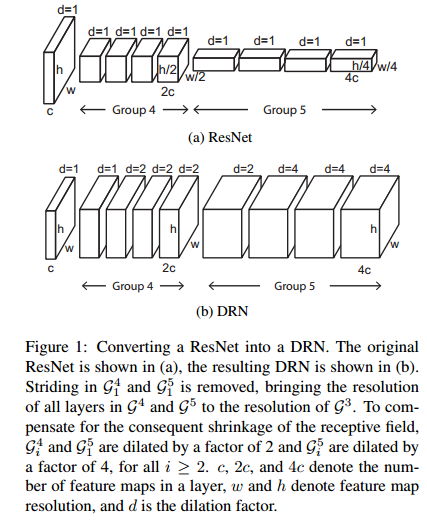
DRN中的Group4和Group5的步长stride变成了1,这导致整个DRN的总步长变为8.
Group4中,第一层 dilation=1,本层感受野没有变,但是后续卷积层的感受野会变小,因此采用dilation=2,维持感受野不变
Group5与原来相比,相当于少了2个stride=2的层,为了维持感受野不变,使dilation=4
这里稍微解释下:
假设输入,输出为:Input: $(N, C_{in}, H_{in}, W_{in})$,Output: $(N, C_{out}, H_{out}, W_{out})$
输出的计算是这样的:

感受野的计算 [参考资料 2,3]。
当然这种方法也是可以加到 Group2和3的,那样就达到总步长为1了,但是这样参数量会很多。文章的分析,步长为8已足够应对,分割这种像素级别的任务了。
以上就是对ResNet的基础改进,比较简单,只加了dilation。
2 Localization
在针对定位或者分割任务时,作者还做了一点改动,如下图:
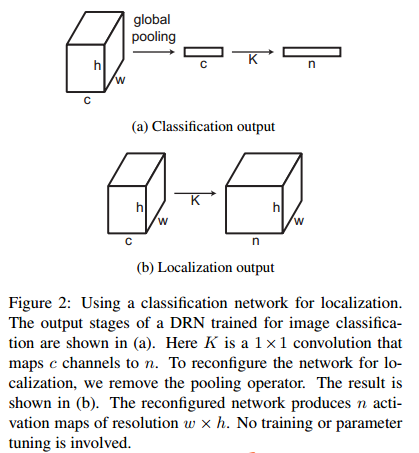
这就是将最后的average global pooling换成了 1×1 卷积,使得输出变成一个channel=n,n为类别数的feature map,这在分割中是比较常见的处理,输出的是一个28×28的score map,而其他文章中比较常用的是14×14大小的score map。28×28明显可以保留更多信息。
做Object Localization时的处理:
假设最后生成的score map是C×W×H的,C为类别,W,H为宽高,对对ImageNet来说就是 1000×28×28.
令 $f(c,w,h)$ 为 坐标 $(w,h)$ 处的激活值后者叫做得分。
那么用下式表示 坐标 $(w,h)$处的类别:
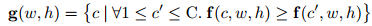
- 坐标 $(w,h)$ 在所有C个类别中,得分最大的作为当前坐标的类别 c
bounding box由下式确定:
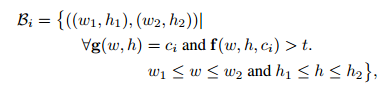
- 类别为 $c_i$ ,且得分大于 阈值 $t$ 的那些坐标集合构成的bounding box
以上bounding box的确定,对于class $c_i$ ,肯定会确定下多个bounding box,使用下式找到与目标最贴切的那个。
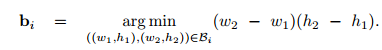
更有趣的是,对这个 Object Localization 可以直接拿 分类网络来做,连fine-tuning都不用了。
3 Degridding
Dilated Convolution 的网格化现象,这是由于空洞卷积本身的问题带来的。
比如下面 (c) 列,feature map上有很明显的网格化现象.

作者也给了一个图来解释,网格化现象产生的原因:
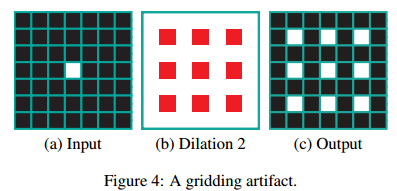
网格化现象会影响网络的性能,于是作者设计了去网格化(Degridding)的结构,如下图:

DRN-A-18与ResNet18的结构类似,只做了stride 和 dilation的转换
DRN-B-26:为了消除网格化现象,在整个网络后面再加两个shortcut block
但是考虑到shortcut block中的shortcut会把输入层直接加到输出,还是会产生网格现象,所以取出shortcut connection
为了消除网格现象,作者的改进方法有如下三种:
Removing max pooling

如上图,考虑到ResNet中 第一个卷积层后面的 max pooling,其提取到的信息高频部分占主要地位(figure 6(b)),这些高频信息会使后续的feature map中的网格化现象加重,因此作者移除了 max pooling 换成了stride=2的卷积层,figure 6(c)作为对比结果。
Adding layers
在网络后面添加 dilation 较小的卷积层,如Figure 5(b),通过网络学习,消除网格现象。
Removing residual connections
因为shortcut connection 的存在,会使 level6(dilation=4)的输出直接加到 level7 的输出上(level7和8也是同样的),因此将shortcut connection 去掉,如Figure 5(c)。
下图是DRN-C结构中不同层的feature map可视化结果:

level5(dilation=2)和level6(dilation=4)的网格现象还比较严重,而最终的 class activation 中的网格现象已经消除的很不错了。
4 Experiments
4.1 Image Classification
Training is performed by SGD with momentum 0.9 and weight decay 10e-4. The learning rate is
initially set to 10e-1 and is reduced by a factor of 10 every 30 epochs. Training proceeds for 120 epochs total.
ImageNet 分类实验,top-1和top-5错误率
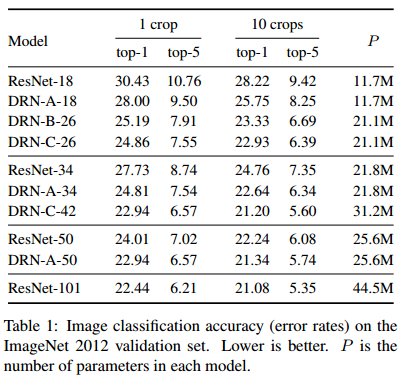
- 同等深度情况下 DRN的效果比ResNet好
- 而且效果 DRN-C > DRN-B > DRN-A ,说明消除网格现象的措施是有用的
- DRN-C-42与 ResNet101的结果相当,而深度只有不到一半,计算量也更少
4.2 Object Localization
在ImageNet上的 Localization结果,也是错误率
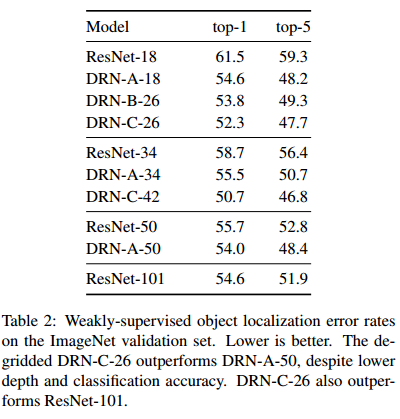
- 还是DRN 好
- DRN-C-26比ResNet101结果都要好,而深度只有26层
- DRN-C比DRN-B和DRN-A效果更好
4.3 Semantic Segmentation
Cityscapes 数据集上的分割结果:
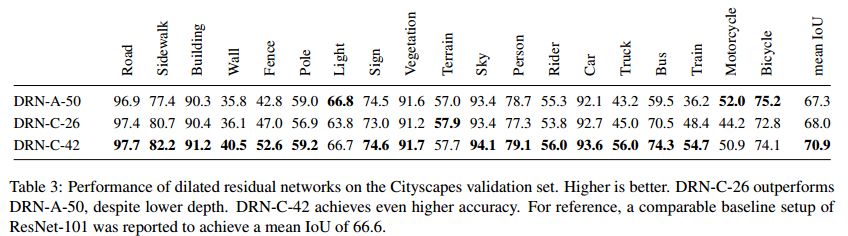
- baseline 是ResNet101,其结果是 66.6,DRN的效果要更好。
- DRN-A-50虽然存在网格化现象,但仍然赶上 ResNet了
- DRN-C-26比DRN-A-50还要好,而网络深度只有一半多一点,说明消除网格很有必要
下图是DRN不同配置的最终分割结果展示,DRN-C-26的结果已经很好了。

5 总结
- 对于分割任务,减少了步长,使最后用于分类的feature map更精细,并将dilated convolution与ResNet结合,保持感受野。
- DRN对于分类,定位,分割的效果均好于以ResNet为backbone的模型。
- 大大减少了网络深度,而且减少了计算量。