1 简介
TensorRT是一个高性能的深度学习推理(Inference)优化器,可以为深度学习应用提供低延迟、高吞吐率的部署推理。TensorRT可用于对超大规模数据中心、嵌入式平台或自动驾驶平台进行推理加速。TensorRT现已能支持TensorFlow、Caffe、Mxnet、Pytorch等几乎所有的深度学习框架,将TensorRT和NVIDIA的GPU结合起来,能在几乎所有的框架中进行快速和高效的部署推理。
TensorRT 是一个C++库,从 TensorRT 3 开始提供C++ API和Python API,主要用来针对 NVIDIA GPU进行 高性能推理(Inference)加速。现在最新版TensorRT是4.0版本。
TensorRT 之前称为GIE。
关于推理(Inference):
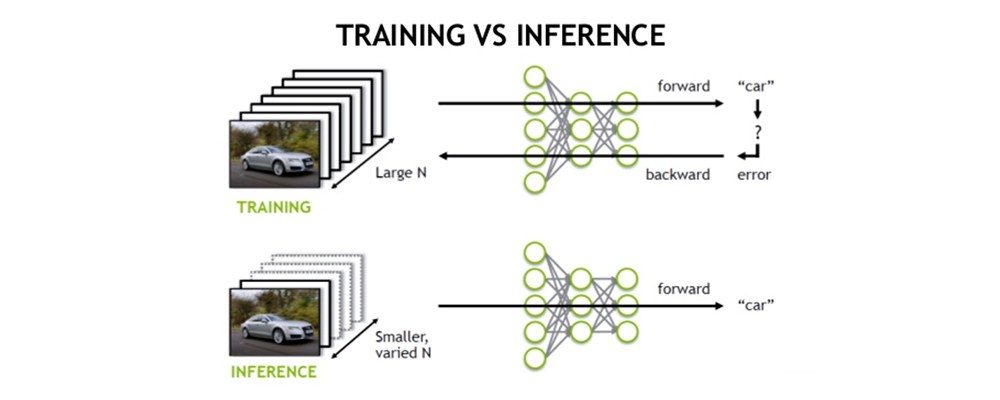
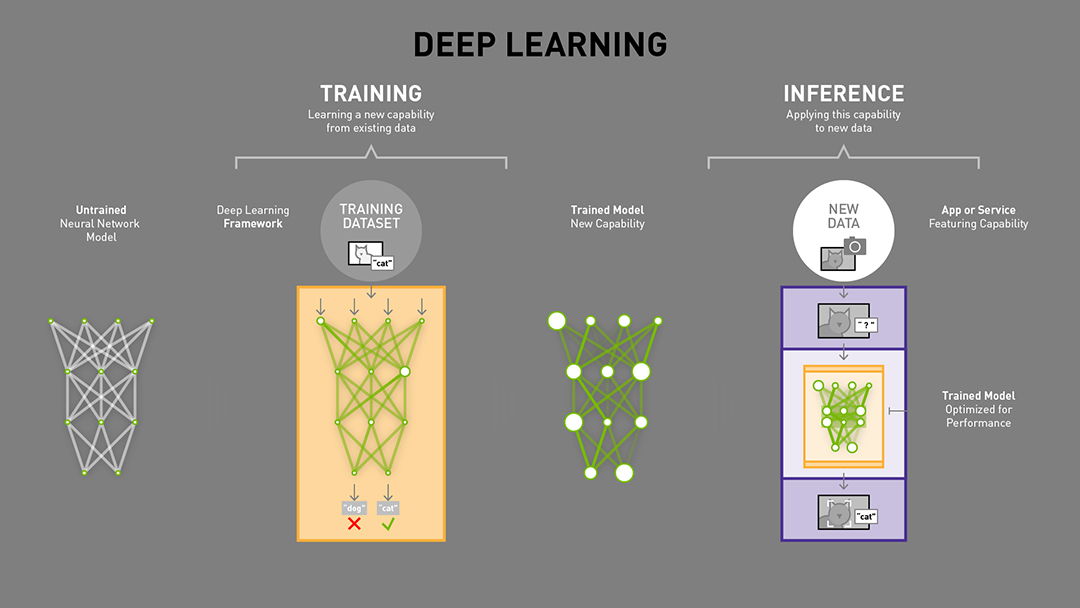
由以上两张图可以很清楚的看出,训练(training)和 推理(inference)的区别:
- 训练(training)包含了前向传播和后向传播两个阶段,针对的是训练集。训练时通过误差反向传播来不断修改网络权值(weights)。
- 推理(inference)只包含前向传播一个阶段,针对的是除了训练集之外的新数据。可以是测试集,但不完全是,更多的是整个数据集之外的数据。其实就是针对新数据进行预测,预测时,速度是一个很重要的因素。
一般的深度学习项目,训练时为了加快速度,会使用多GPU分布式训练。但在部署推理时,为了降低成本,往往使用单个GPU机器甚至嵌入式平台(比如 NVIDIA Jetson)进行部署,部署端也要有与训练时相同的深度学习环境,如caffe,TensorFlow等。
由于训练的网络模型可能会很大(比如,inception,resnet等),参数很多,而且部署端的机器性能存在差异,就会导致推理速度慢,延迟高。这对于那些高实时性的应用场合是致命的,比如自动驾驶要求实时目标检测,目标追踪等。
所以为了提高部署推理的速度,出现了很多轻量级神经网络,比如squeezenet,mobilenet,shufflenet等。基本做法都是基于现有的经典模型提出一种新的模型结构,然后用这些改造过的模型重新训练,再重新部署。
而tensorRT 则是对训练好的模型进行优化。 tensorRT就只是 推理优化器。当你的网络训练完之后,可以将训练模型文件直接丢进tensorRT中,而不再需要依赖深度学习框架(Caffe,TensorFlow等),如下:
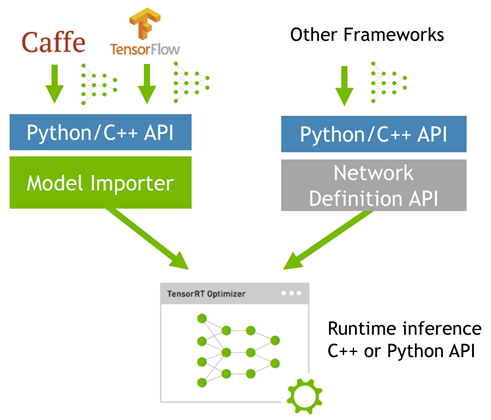
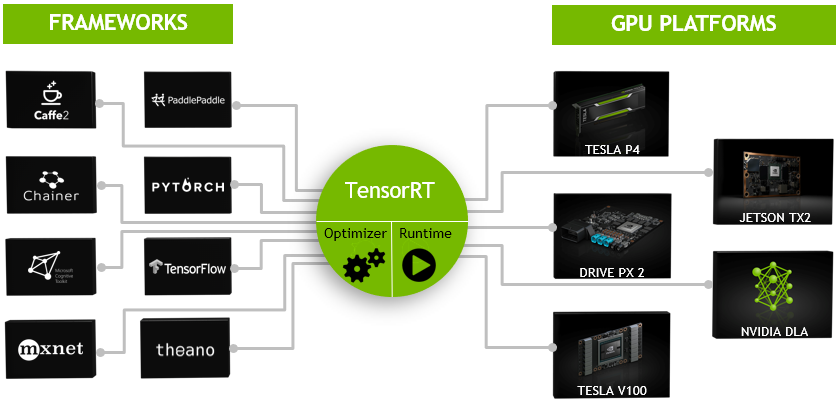
可以认为tensorRT是一个只有前向传播的深度学习框架,这个框架可以将 Caffe,TensorFlow的网络模型解析,然后与tensorRT中对应的层进行一一映射,把其他框架的模型统一全部 转换到tensorRT中,然后在tensorRT中可以针对NVIDIA自家GPU实施优化策略,并进行部署加速。
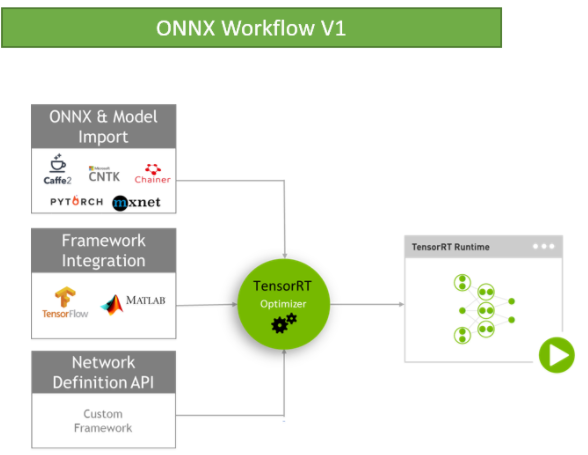
目前TensorRT4.0 几乎可以支持所有常用的深度学习框架,对于caffe和TensorFlow来说,tensorRT可以直接解析他们的网络模型;对于caffe2,pytorch,mxnet,chainer,CNTK等框架则是首先要将模型转为 ONNX 的通用深度学习模型,然后对ONNX模型做解析。而tensorflow和MATLAB已经将TensorRT集成到框架中去了。
ONNX(Open Neural Network Exchange )是微软和Facebook携手开发的开放式神经网络交换工具,也就是说不管用什么框架训练,只要转换为ONNX模型,就可以放在其他框架上面去inference。这是一种统一的神经网络模型定义和保存方式,上面提到的除了tensorflow之外的其他框架官方应该都对onnx做了支持,而ONNX自己开发了对tensorflow的支持。从深度学习框架方面来说,这是各大厂商对抗谷歌tensorflow垄断地位的一种有效方式;从研究人员和开发者方面来说,这可以使开发者轻易地在不同机器学习工具之间进行转换,并为项目选择最好的组合方式,加快从研究到生产的速度。
上面图中还有一个 Netwok Definition API 这个是为了给那些使用自定义的深度学习框架训练模型的人提供的TensorRT接口。举个栗子:比如 YOLO 作者使用的darknet要转tensorrt估计得使用这个API,不过一般网上有很多使用其他框架训练的YOLO,这就可以使用对应的caffe/tensorflow/onnx API了。
ONNX / TensorFlow / Custom deep-learning frame模型的工作方式:
现在tensorRT支持的层有:
- Activation: ReLU, tanh and sigmoid
- Concatenation : Link together multiple tensors across the channel dimension.
- Convolution: 3D,2D
- Deconvolution
- Fully-connected: with or without bias
- ElementWise: sum, product or max of two tensors
- Pooling: max and average
- Padding
- Flatten
- LRN: cross-channel only
- SoftMax: cross-channel only
- RNN: RNN, GRU, and LSTM
- Scale: Affine transformation and/or exponentiation by constant values
- Shuffle: Reshuffling of tensors , reshape or transpose data
- Squeeze: Removes dimensions of size 1 from the shape of a tensor
- Unary: Supported operations are exp, log, sqrt, recip, abs and neg
- Plugin: integrate custom layer implementations that TensorRT does not natively support.
基本上比较经典的层比如,卷积,反卷积,全连接,RNN,softmax等,在tensorRT中都是有对应的实现方式的,tensorRT是可以直接解析的。
但是由于现在深度学习技术发展日新月异,各种不同结构的自定义层(比如:STN)层出不穷,所以tensorRT是不可能全部支持当前存在的所有层的。那对于这些自定义的层该怎么办?
tensorRT中有一个 Plugin 层,这个层提供了 API 可以由用户自己定义tensorRT不支持的层。 如下图:
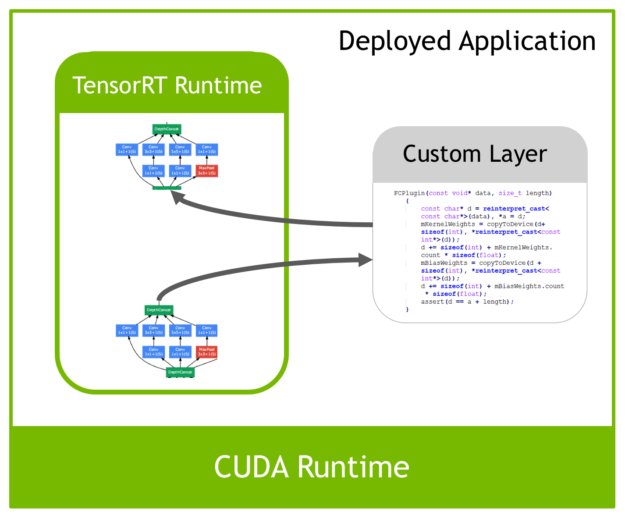
这就解决了适应不同用户的自定义层的需求。
2 优化方式
TentsorRT 优化方式:
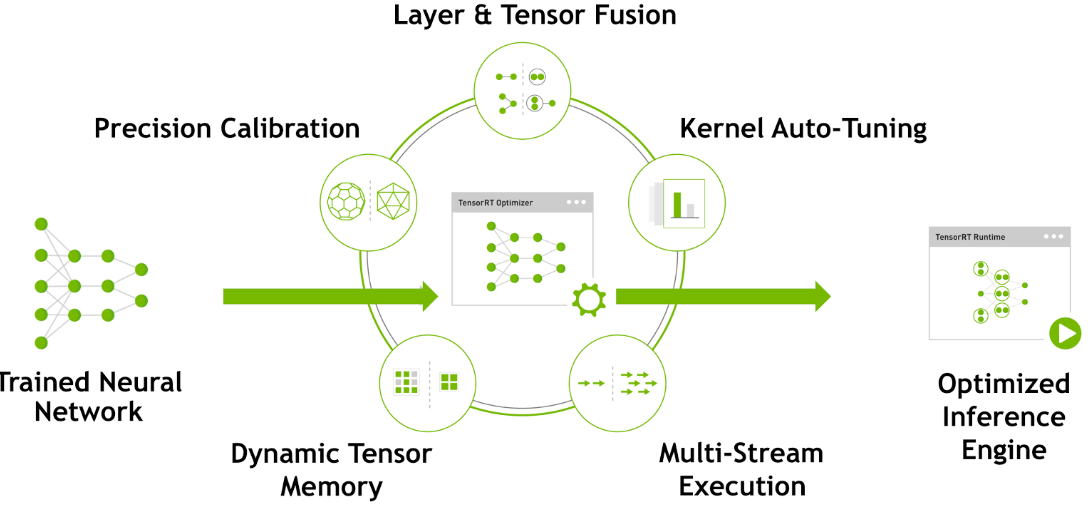
TensorRT优化方法主要有以下几种方式,最主要的是前面两种。
层间融合或张量融合(Layer & Tensor Fusion)
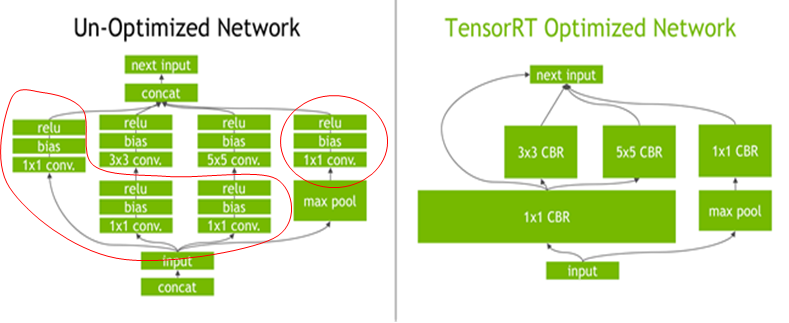
如下图左侧是GoogLeNetInception模块的计算图。这个结构中有很多层,在部署模型推理时,这每一层的运算操作都是由GPU完成的,但实际上是GPU通过启动不同的CUDA(Compute unified device architecture)核心来完成计算的,CUDA核心计算张量的速度是很快的,但是往往大量的时间是浪费在CUDA核心的启动和对每一层输入/输出张量的读写操作上面,这造成了内存带宽的瓶颈和GPU资源的浪费。TensorRT通过对层间的横向或纵向合并(合并后的结构称为CBR,意指 convolution, bias, and ReLU layers are fused to form a single layer),使得层的数量大大减少。横向合并可以把卷积、偏置和激活层合并成一个CBR结构,只占用一个CUDA核心。纵向合并可以把结构相同,但是权值不同的层合并成一个更宽的层,也只占用一个CUDA核心。合并之后的计算图(图4右侧)的层次更少了,占用的CUDA核心数也少了,因此整个模型结构会更小,更快,更高效。
数据精度校准(Weight &Activation Precision Calibration)
大部分深度学习框架在训练神经网络时网络中的张量(Tensor)都是32位浮点数的精度(Full 32-bit precision,FP32),一旦网络训练完成,在部署推理的过程中由于不需要反向传播,完全可以适当降低数据精度,比如降为FP16或INT8的精度。更低的数据精度将会使得内存占用和延迟更低,模型体积更小。
如下表为不同精度的动态范围:
| Precision | Dynamic Range |
|---|---|
| FP32 | $-3.4×10^{38} ~ +3.4×10^{38}$ |
| FP16 | $-65504 ~ +65504$ |
| INT8 | $-128 ~ +127$ |
INT8只有256个不同的数值,使用INT8来表示 FP32精度的数值,肯定会丢失信息,造成性能下降。不过TensorRT会提供完全自动化的校准(Calibration )过程,会以最好的匹配性能将FP32精度的数据降低为INT8精度,最小化性能损失。关于校准过程,后面会专门做一个探究。
Kernel Auto-Tuning
网络模型在推理计算时,是调用GPU的CUDA核进行计算的。TensorRT可以针对不同的算法,不同的网络模型,不同的GPU平台,进行 CUDA核的调整(怎么调整的还不清楚),以保证当前模型在特定平台上以最优性能计算。
TensorRT will pick the implementation from a library of kernels that delivers the best performance for the target GPU, input data size, filter size, tensor layout, batch size and other parameters.
Dynamic Tensor Memory
在每个tensor的使用期间,TensorRT会为其指定显存,避免显存重复申请,减少内存占用和提高重复使用效率。
Multi-Stream Execution
Scalable design to process multiple input streams in parallel,这个应该就是GPU底层的优化了。
3 安装
这里 是英伟达提供的安装指导,如果有仔细认真看官方指导,基本上按照官方的指导肯定能安装成功。
问题是肯定有很多人不愿意认真看英文指导,比如说我就是,我看那个指导都是直接找到命令行所在,直接敲命令,然后就出了很多问题,然后搜索好长时间,最后才发现,原来官方install guide里是有说明的。
这里使用的是 deb 包安装的方式,以下是安装过程,我是cuda 8.0 ,cuda9.0也是类似的。
进行下面三步时最好先将后面记录的遇到的问题仔细看看,然后回过头来按照 一二三 步来安装。
第一步:
|
|
其中的deb包要换成与自己 cuda和系统 对应的版本。
第二步:
使用python2则安装如下依赖
|
|
这个是为了安装一些依赖的:比如 python-libnvinfer python-libnvinfer-dev swig3.0
如果是python3则安装如下依赖
|
|
第三步:
|
|
这个是安装通用文件格式转换器,主要用在 TensorRT 与TensorFlow 交互使用的时候。
不过我安装的时候还是出问题了:
安装tensorRT之前要将cuda的两个deb包添加上,因为TensorRT依赖好多cuda的一些东西比如
cuda-cublas-8-0,我之前cuda是用runfile安装的,所以TensorRT安装时有些依赖库找不到导致出错,如下图: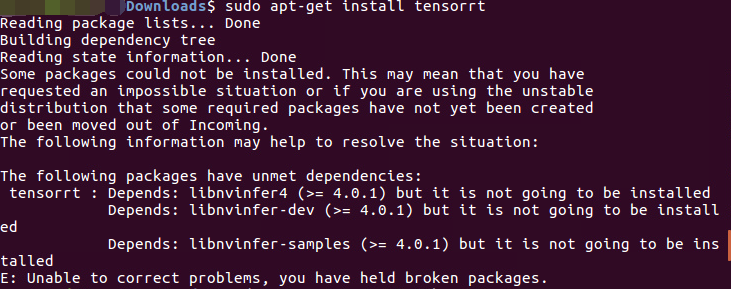
上面提示缺少依赖包,但是实际上
libnvinfer4的包是tensorRT安装了之后才有的,那现在反而成了依赖包了,不管他,缺什么安装什么,但是还是出错,如下: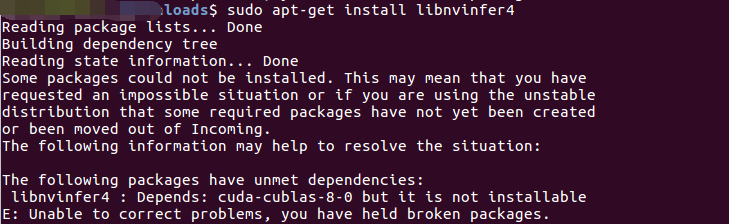
哇,还是缺少依赖包,这次是缺 cuda-cublas-8-0 ,现在知道了,缺的是cuda的相关组件。
后来把 cuda 的两个deb包安装之后就没问题了,cuda 8.0 的deb包 在这里 ,如下图,下载红框里的两个deb包。
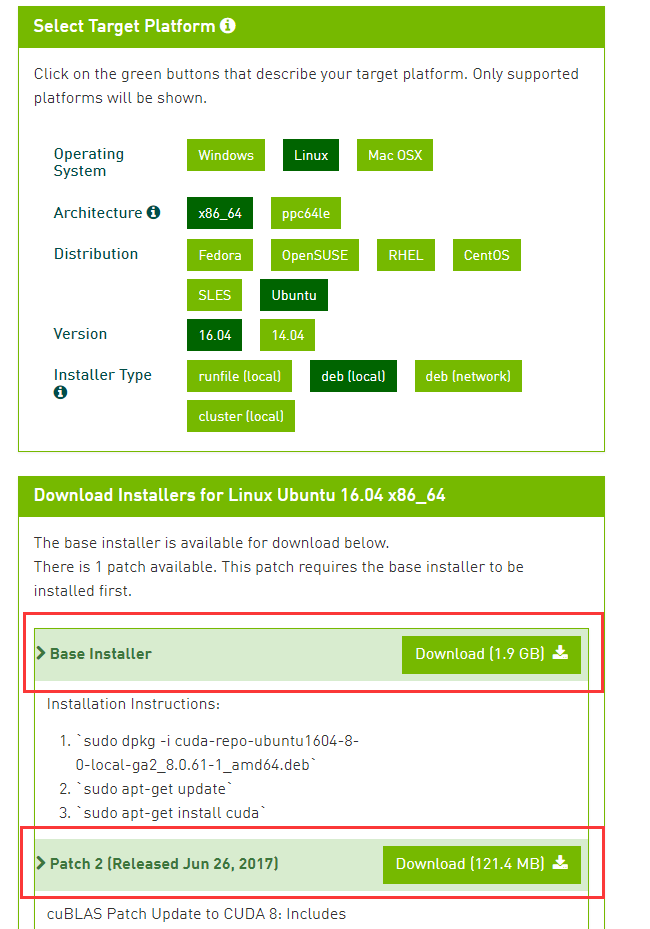
如果用的是 runfile 的方式安装的cuda的话,很容易出错,因为网上大部分cuda安装教程都是用runfile的方式安装的。所以如果cuda就是用deb包安装的话,就没有这个问题,如果使用runfile安装的话,安装tensorRT之前要把这两个deb包安装上,安装方式如下:
|
|
以上是自己摸索出来的,折腾了一番之后才发现原来官方的 install guide已经说明了,如下:
The debian installation automatically installs any dependencies, but:
- requires sudo root privileges to install
- provides no flexibility as to which location TensorRT is installed into
- requires that the CUDA Toolkit has also been installed with a debian package.
注意最后一条,意思是如果用deb包安装TensorRT,那么前提是 你的CUDA也是用deb包安装的。
怪自己没有认真看,要是多花个5分钟仔细看一下,就不用折腾这么久了,由此深有感触,文档还是官方英文原版的最好,而且要认真看。
不过不知道用 runfile cuda+Tar File Installation tensorRT的组合安装方式是怎么样的,没试过。
tensorRT 3 支持CUDA 8 和 CUDA 9,但是只支持 cuDNN 7,我第一次安装的时候cuDNN是5.1的,结果总是出错,错误是啥忘记了,反正换成cuDNN 7就好了,这个官方指导也有说明,不过比较隐蔽,他是放在 4.2 Tar File Installation 一节说明的:
- Install the following dependencies, if not already present:
‣ Install the CUDA Toolkit v8.0, 9.0 or 9.2
‣ cuDNN 7.1.3
‣ Python 2 or Python 3
我试过只要大版本是 cudnn7就可以。这个也容易忽略。
- Install the following dependencies, if not already present:
安装好后,使用 $ dpkg -l | grep TensorRT 命令检测是否成功,输出如下所示即为成功
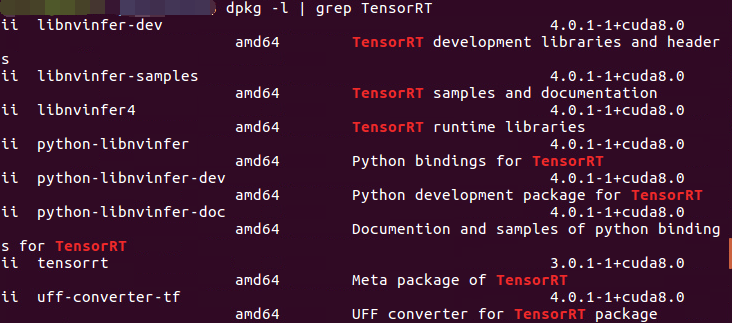
安装后会在 /usr/src 目录下生成一个 tensorrt 文件夹,里面包含 bin , data , python , samples 四个文件夹, samples 文件夹中是官方例程的源码; data , python 文件中存放官方例程用到的资源文件,比如caffemodel文件,TensorFlow模型文件,一些图片等;bin 文件夹用于存放编译后的二进制文件。
可以把 tensorrt 文件夹拷贝到用户目录下,方便自己修改测试例程中的代码。
进入 samples 文件夹直接 make,会在 bin 目录中生成可执行文件,可以一一进行测试学习。
另外tensorRT是不开源的, 它的头文件位于 /usr/include/x86_64-linux-gnu 目录下,共有七个,分别为:
|
|
TensorRT4.0相比于3.0新增了对ONNX的支持。
tensorRT的库文件位于 /usr/lib/x86_64-linux-gnu 目录下,如下(筛选出来的,掺杂了一些其他nvidia库):
|
|
编译
将 /usr/src/tensorrt 文件夹拷贝到用户目录下,假设路径为 <tensorrt_srcpath> 。
第一个问题:
在 <tensorrt_srcpath>/tensorrt/samples 文件夹中有个 Makefile.config 文件,里面第4行:
|
|
这一句是为了获取cuda版本的,我的机器是 CUDA 8.0 。我记得我第一次安装时,后面dpkg命令 输出的不是8.0,是一个很奇怪的数字,导致我不能编译 tensorRT 例程。 后来我直接在这句后面添加了一句: CUDA_VER=cuda-8.0 ,简单粗暴解决问题了。
这个问题好像是还是因为我之前安装 cuda 时是用 runfile 的方式安装的,用这种方式安装的cuda不会安装cuda的deb包,所以上面语句输出的是不对的,导致找不到cuda库目录,编译不能进行。
可以使用命令sudo dpkg -i cuda-repo-ubuntu1604-8-0-local-ga2_8.0.61-1_amd64.deb ,安装deb包,就可以了。或者像我那样添加 CUDA_VER=cuda-8.0 也可以。
如果安装cuda就是使用deb包安装的话,就不会出现这个问题。
第二个问题:
如果机器上安装了多个cuda版本,像我这个机器上 cuda8.0,9.0,9.1都装上了,上面语句得到的就只是 CUDA_VER=9.1,如果安装的是其他版本cuda的TensorRT的话肯定是不对的。
可以直接在第4行下面添加:
|
|
3 TensorRT 使用流程
这是个很简单的流程,先简单了解一下,以后会深入研究更高级的用法。
在使用tensorRT的过程中需要提供以下文件(以caffe为例):
- A network architecture file (deploy.prototxt), 模型文件
- Trained weights (net.caffemodel), 权值文件
- A label file to provide a name for each output class. 标签文件
前两个是为了解析模型时使用,最后一个是推理输出时将数字映射为有意义的文字标签。
tensorRT的使用包括两个阶段, build and deployment:
- build:Import and optimize trained models to generate inference engines
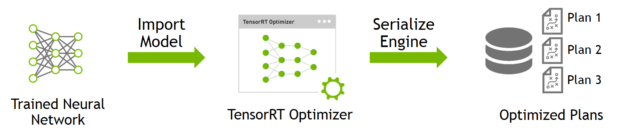
build阶段主要完成模型转换(从caffe或TensorFlow到TensorRT),在模型转换时会完成前述优化过程中的层间融合,精度校准。这一步的输出是一个针对特定GPU平台和网络模型的优化过的TensorRT模型,这个TensorRT模型可以序列化存储到磁盘或内存中。存储到磁盘中的文件称之为 plan file。
下面代码是一个简单的build过程:
|
|
上面的过程使用了一个高级别的API:CaffeParser,直接读取 caffe的模型文件,就可以解析,也就是填充network对象。解析的过程也可以直接使用一些低级别的C++API,比如:
|
|
解析caffe模型之后,必须要指定输出tensor,设置batchsize,和设置工作空间。设置batchsize就跟使用caffe测试是一样的,设置工作空间是进行前述层间融合和张量融合的必要措施。层间融合和张量融合的过程是在调用builder->buildCudaEngine时才进行的。
- deploy:Generate runtime inference engine for inference

deploy阶段主要完成推理过程,Kernel Auto-Tuning 和 Dynamic Tensor Memory 应该是在这里完成的。将上面一个步骤中的plan文件首先反序列化,并创建一个 runtime engine,然后就可以输入数据(比如测试集或数据集之外的图片),然后输出分类向量结果或检测结果。
tensorRT的好处就是不需要安装其他深度学习框架,就可以实现部署和推理。
以下是一个简单的deploy代码:这里面没有包含反序列化过程和测试时的batch流获取
|
|
可见使用了挺多的CUDA 编程,所以要想用好tensorRT还是要熟练 GPU编程。
4 Performance Results
来看一看使用以上优化方式之后,能获得怎样的加速效果:
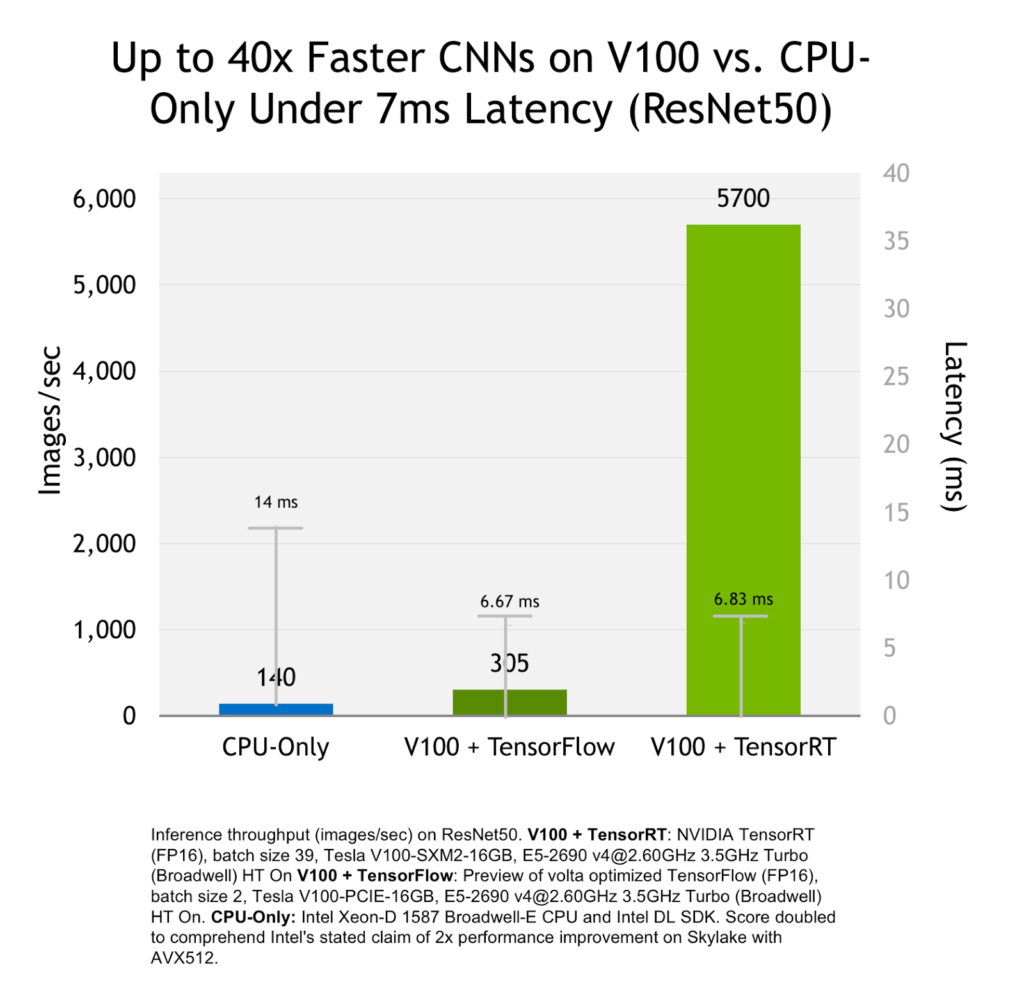
可见使用tensorRT与使用CPU相比,获得了40倍的加速,与使用TensorFlow在GPU上推理相比,获得了18倍的加速。效果还是很明显的。
以下两图,是使用了INT8低精度模式进行推理的结果展示:包括精度和速度。
来自:GTC 2017,Szymon Migacz 的PPT
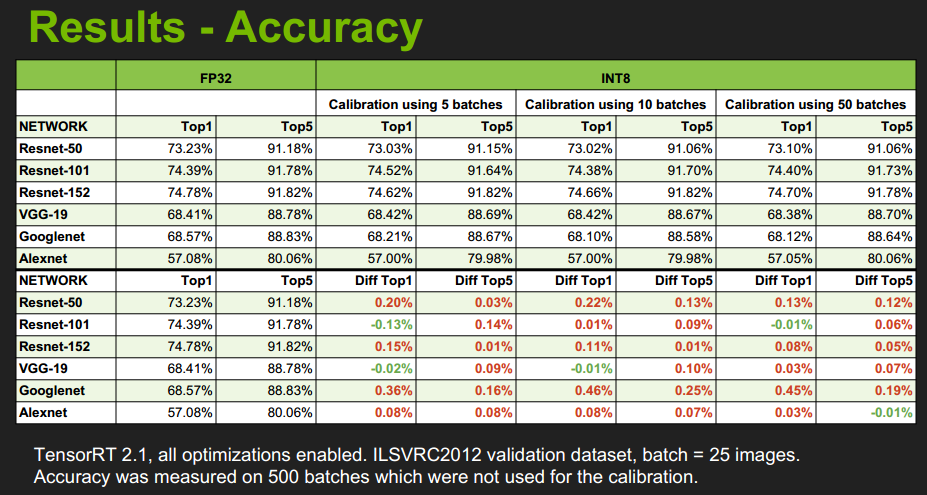
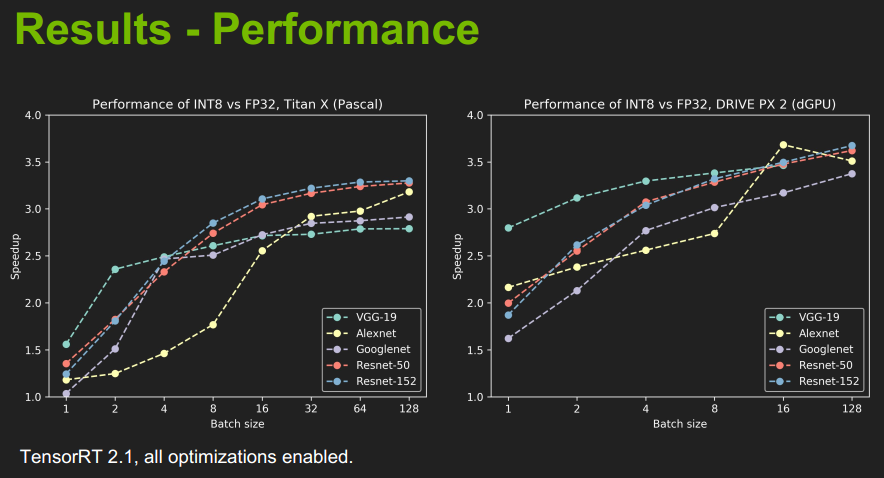
可见精度损失很少,速度提高很多。
上面还是17年 TensorRT2.1的性能,这里 是一个最新的TensorRT4.0.1的性能表现,有很详细的数据展示来说明TensorRT在inference时的强劲性能。
后面的博客中会进一步学习 tensorRT,包括官方例程和做一些实用的优化。
参考资料
- What’s the Difference Between Deep Learning Training and Inference?
- Discover the Difference Between Deep Learning Training and Inference
- GTC 2017,Szymon Migacz 的PPT
- NVIDIA TensorRT | NVIDIA Developer
- Deploying Deep Neural Networks with NVIDIA TensorRT
- TensorRT 3: Faster TensorFlow Inference and Volta Support
- tensorRT installation guide
- cuda installation guide
- NVIDIA TensorRT Performance Guide
- TensorRT 4 Accelerates Neural Machine Translation, Recommenders, and Speech
- ONNX