结合 tensorRT官方给出的一个例程,介绍tensorRT的使用。
这个例程是mnist手写体识别。例程位于目录: /usr/src/tensorrt/samples/sampleMNIST
文件结构:
|
|
主要是 sampleMNIST.cpp 文件, common.cpp 文件主要提供 读取文件的函数和 Logger对象。
main
|
|
实际上从第93行创建 IRuntime对象时,就可以认为是属于deploy了。
最后输出是这样的:读进一张9,输出一个结果:

其中最重要的两个函数 caffeToTRTModel( ) 和 doInference( )分别完成的是build和deploy的功能。
Build Phase
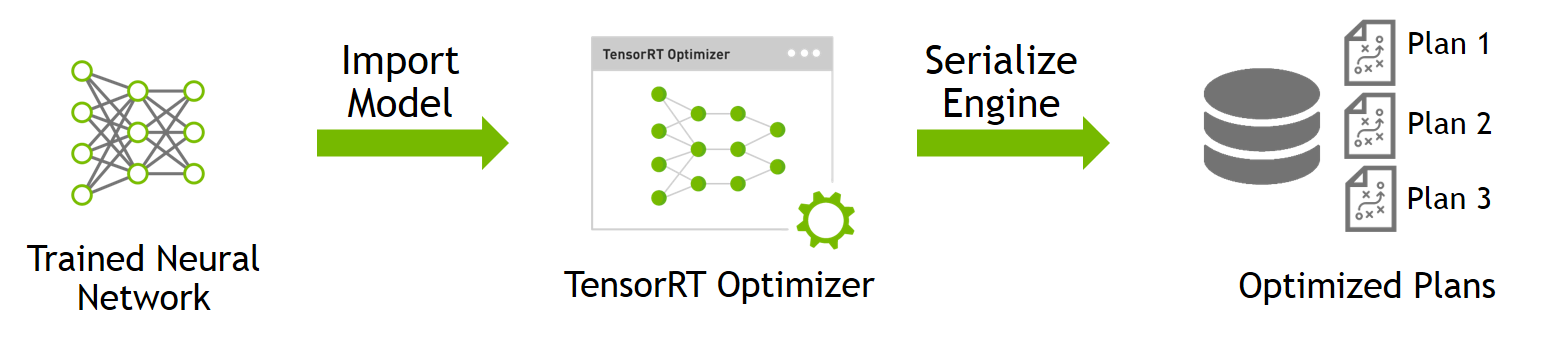
将Caffe model 转换为 TensorRT object,首先使用其他深度学习框架训练好模型,然后丢进tensorRT优化器中进行优化,优化后会产生一个文件,这个文件可以认为是优化后的模型,接着使用序列化方法将这个优化好后的模型存储在磁盘上,存储到磁盘上的文件称为 plan file。
这个阶段需要给tensorRT提供两个文件,分别是
- 网络模型文件(比如,caffe的deploy.prototxt)
- 训练好的权值文件(比如,caffe的net.caffemodel)
除此之外,还需要明确 batch size,并指明输出层。
mnist例程中的caffe模型解析代码:标志是创建 IBuilder对象。
|
|
Deploy Phase

Deploy 阶段需要文件如下:
- 标签文件(这个主要是将模型产生的数字标号分类,与真实的名称对应起来),不过这个例子中就不需要了,因为MNIST的真实分类就是数字标号。
Deploy 阶段可以认为从主函数中就已经开始了。标志是创建 IRuntime 对象。
|
|
其中 doInference函数的详细内容如下:
|
|
辅助函数
用到 common.cpp 文件中的辅助函数:locateFile( ) 和 readPGMFile( )
|
|
日志类
common.h文件中有个日志类: class Logger : public nvinfer1::ILogger
这是一个日志类,继承自 nvinfer1::ILogger
|
|
nvinfer1::ILogger 这个类位于 tensorRT头文件 NvInfer.h 中,此文件路径: /usr/include/x86_64-linux-gnu/NvInfer.h
把 ILogger 类摘出来:
|
|
可见这个类 是 builder, engine and runtime 的一个日志接口,这个类应该以单例模式使用。即当有多个IRuntime 和/或 IBuilder 对象时,也只能使用同一个ILogger接口。
这个接口中有个枚举类 enum class Severity 定义了日志报告级别,分别为 kINTERNAL_ERROR,kERROR,kWARNING和kINFO;然后还有一个纯虚函数 log( ) ,用户可以自定义这个函数,以实现不同效果的打印。
比如common.h 文件中Logger类的 log()函数,就是根据不同的报告级别向标准错误输出流输出带有不同前缀的信息。这个地方是可以自己定义的,比如你可以设置为输出信息到文件流然后把信息保存到txt文件中等。
以上就是使用tensorRT优化MNIST的LeNet的一个简单的例子,其实对于mnist来说,使用tensorRT加速的意义不大,因为这个模型本来就比较小,这里使用这个例子主要是为了学习tensorRT的用法。