1 mAP简介
目标检测里面经常用到的评估标准是:mAP(mean average precision),计算mAP需要涉及到precision 和 recall的计算,mAP,precision,recall的定义含义以及计算方式,网上很多博客都有说明,本文不打算重述。
阅读本文之前,请先仔细阅读如下资料:
- 周志华老师 《机器学习》 模型评估标准一节,主要是precision,recall的计算方式,或者自己网上搜博客
- 多标签图像分类任务的评价方法-mAP 通过一个简单的二分类阐述 mAP的含义与计算
- average precision 几种不同形式 AP 的计算方式与异同
以博客 多标签图像分类任务的评价方法-mAP 中的数据为例,下面是这个二分类问题的P-R曲线(precision-recall curve),P-R曲线下面与x轴围成的面积称为 average precision。
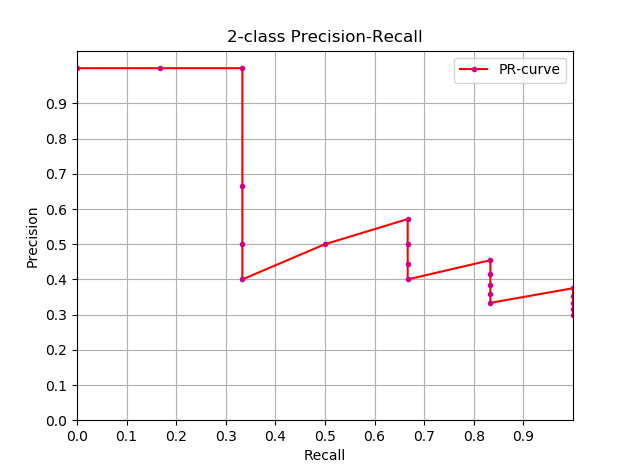
那么问题就在于如何计算AP,这里很显然可以通过积分来计算
$$
AP=\int_0^1 P(r) dr
$$
但通常情况下都是使用估算或者插值的方式计算:
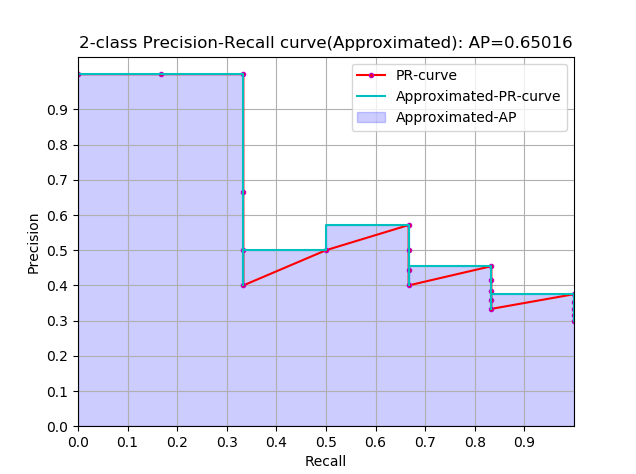
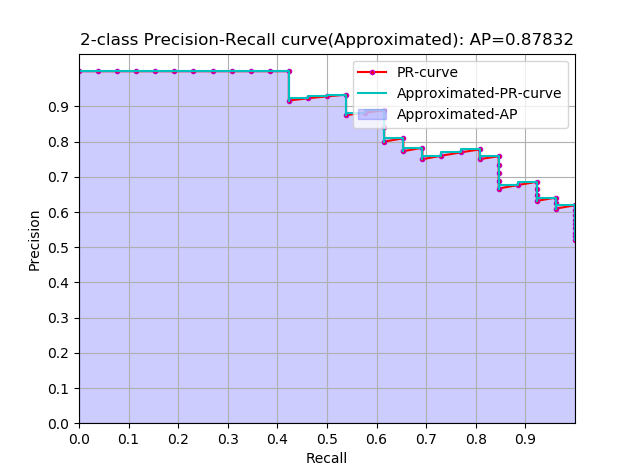
approximated average precision
$$
AP=\sum_{k=1}^N P(k) \Delta r(k)
$$
这个计算方式称为 approximated 形式的,插值计算的方式里面这个是最精确的,每个样本点都参与了计算
很显然位于一条竖直线上的点对计算AP没有贡献
这里N为数据总量,k为每个样本点的索引, $\Delta r(k)=r(k)-r(k-1)$
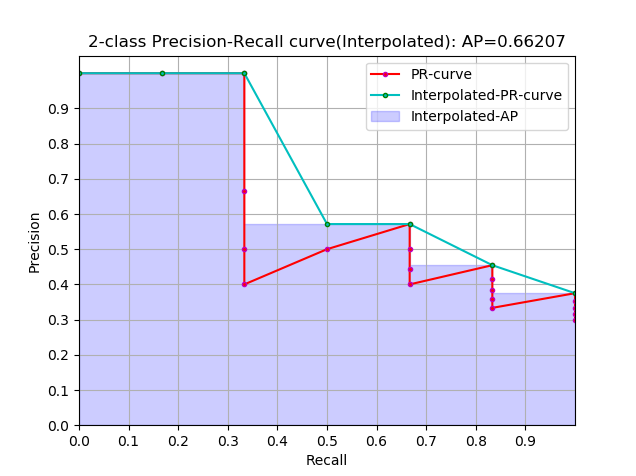
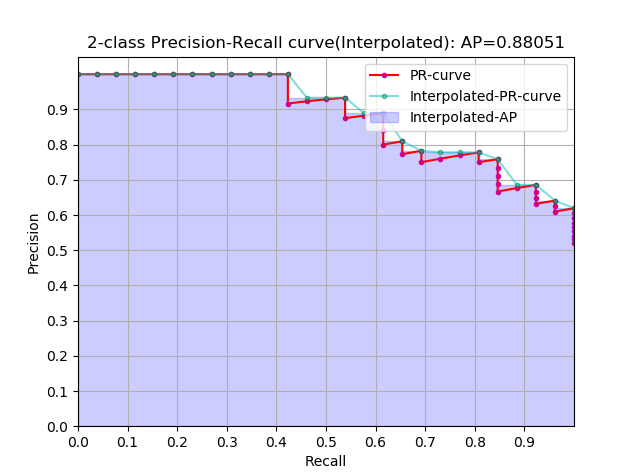
Interpolated average precision
这是一种插值计算方式:
$$
P_{interp}(k)=max_{\hat k \ge k} P(\hat k)
$$
$$
\sum_{k=1}^N P_{interp(k)} \Delta r(k)
$$
- k 为每一个样本点的索引,参与计算的是所有样本点
- $P_{interp}(k)$ 取第 k 个样本点之后的样本中的最大值
- 这种方式不常用,所以不画图了
插值方式进一步演变:
$$
P_{interp}(k)=max_{\hat k \ge k} P(\hat k)
$$
$$
\sum_{k=1}^K P_{interp}(k) \Delta r(k)
$$
这是通常意义上的 Interpolated 形式的 AP,这种形式使用的是比较多的,因为这个式子跟上面提到的计算方式在最终的计算结果上来说是一样的,上面那个式子的曲线跟这里图中阴影部分的外部轮廓是一样的
当一组数据中的正样本有K个时,那么recall的阈值也有K个,k代表阈值索引,参与计算的只有K个阈值所对应的样本点
$P_{interp}(k)$ 取第 k 个阈值所对应的样本点之后的样本中的最大值
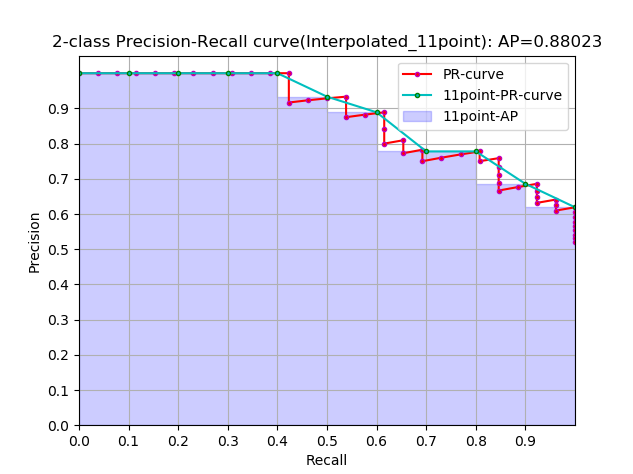
再进一步演变:
$$
P_{interp}(k)=max_{r(\hat k) \ge R(k)} P(\hat k) \quad R \in \{0,0.1,0.2,…,1.0\}
$$
$$
\sum_{k=1}^K P_{interp}(k) \Delta r(k)
$$
这是通常意义上的 11points_Interpolated 形式的 AP,选取固定的 $\{0,0.1,0.2,…,1.0\}$ 11个阈值,这个在PASCAL2007中有使用
这里因为参与计算的只有11个点,所以 K=11,称为11points_Interpolated,k为阈值索引
$P_{interp}(k)$ 取第 k 个阈值所对应的样本点之后的样本中的最大值,只不过这里的阈值被限定在了 $\{0,0.1,0.2,…,1.0\}$ 范围内。
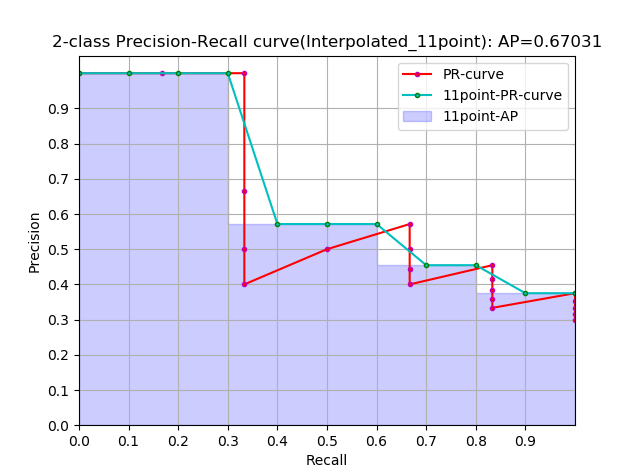
从曲线上看,真实 AP< approximated AP < Interpolated AP
11-points Interpolated AP 可能大也可能小,当数据量很多的时候会接近于 Interpolated AP
前面的公式中计算AP时都是对PR曲线的面积估计,然后我看到PASCAL的论文里给出的公式就更加简单粗暴了,如下:
$$
AP=\frac{1}{11} \sum_{r \in \{ 0,0.1,0.2,…,1.0 \}} P_{intep} (r)
$$
$$
P_{interp}(r)=MAX_{\hat r: \hat r\ge r} P(\hat r)
$$
直接计算11个阈值处的precision的平均值。
不过我看 Itroduction to Modern Information(中译本:王斌《信息检索导论》)一书中也是直接计算平均值的。
对于Interpolated 形式的 AP,因为recall的阈值变化是等差的(或者recall轴是等分的),所以计算面积和直接计算平均值结果是一样的,
对于11points_Interpolated 来说,虽然recall的阈值也是等差的,但是11points计算平均值时会把recall=0那一点的precision算进去,但实际上那一点是人为添加的,所以计算面积和直接计算平均值会有略微差异。
实际上这是一个极限问题,如果recall轴等分且不考虑初始点,那么计算面积和均值的结果是一样的;如果不等分,只有当分割recall无限多的时候,二者无限趋近,这是一个数学问题。
第 4 节的代码包含这两种计算方式,可以用来验证。
以上几种不同形式的 AP 在第4节会有简单的代码实现。
2 PASCAL数据集mAP计算方式
一定要先看这个博客 多标签图像分类任务的评价方法-mAP 。
PASCAL VOC最终的检测结构是如下这种格式的:
比如comp3_det_test_car.txt:
|
|
每一行依次为 :
|
|
每一行都是一个bounding box,后面四个数定义了检测出的bounding box的左上角点和右下角点的坐标。
在计算mAP时,如果按照二分类问题理解,那么每一行都应该对应一个标签,这个标签可以通过ground truth计算出来。
但是如果严格按照 ground truth 的坐标来判断这个bounding box是否正确,那么这个标准就太严格了,因为这是属于像素级别的检测,所以PASCAL中规定当一个bounding box与ground truth的 IOU>0.5 时就认为这个框是正样本,标记为1;否则标记为0。这样一来每个bounding box都有个得分,也有一个标签,这时你可以认为前面的文件是这样的,后面多了一个标签项:
|
|
进而你可以认为是这样的,后面的标签实际上是通过坐标计算出来的
|
|
这样一来就可以根据前面博客中的二分类方法计算AP了。但这是某一个类别的,将所有类别的都计算出来,再做平均即可得到mAP.
3 COCO数据集AP计算方式
COCO数据集里的评估标准比PASCAL 严格许多
COCO检测出的结果是json文件格式,比如下面的:
|
|
我们还是按照前面的形式来便于理解:
|
|
前面提到可以使用IOU来计算出一个标签,PASCAL用的是 IOU>0.5即认为是正样本,但是COCO要求IOU阈值在[0.5, 0.95]区间内每隔0.05取一次,这样就可以计算出10个类似于PASCAL的mAP,然后这10个还要再做平均,即为最后的AP,COCO中并不将AP与mAP做区分,许多论文中的写法是 AP@[0.5:0.95]。而COCO中的 AP@0.5 与PASCAL 中的mAP是一样的。
4 代码简单实现
一定要先看这个博客 多标签图像分类任务的评价方法-mAP 。
计算AP的代码上,我觉得可以看看sklearn关于AP计算的源码,必要时可以逐步调试以加深理解。
sklearn的average_precision_score API,average_precision_score 源码
sklearn上的一个计算AP的例子 Precision-Recall and average precision compute
另外PASCAL和COCO都有公开的代码用于评估标准的计算
PASCAL development kit code and documentation
下面是仿照sklearn上的计算AP的例子写的一个简单的代码,与sklearn略有差异并做了一些扩展,这个代码可以计算 approximated,interpolated,11point_interpolated形式的AP,sklearn的API只能计算approximated形式的AP。这几个形式的AP的差异,参考 average precision 这个博客。PASCAL2007的测量标准用的 11point_interpolated形式,而 PASCAL2010往后使用的是 interpolated 形式的。
从计算的精确度上 approximated > interpolated > 11point_interpolated,当然最精确的是积分。
|
|
这个例子使用了 鸢尾花数据集中的两类构建了一个SVM分类器,然后对分类结果计算AP.
最终的结果如下所示:
参考资料
- 周志华老师 《机器学习》
- 多标签图像分类任务的评价方法-mAP
- average precision
- 王斌译 《信息检索导论》
- 论文: The PASCAL Visual Object Classes (VOC) Challenge 2007 和 2012
- http://cocodataset.org/#detection-eval
- http://host.robots.ox.ac.uk/pascal/VOC/
- http://scikit-learn.org/stable/modules/generated/sklearn.metrics.average_precision_score.html