前面几节以 LeNet 为例主要介绍了 tensorRT 的简单使用流程。包括,使用 tensorRT 的 NvCaffeParser 工具以及底层 C++ API 来 模型 caffe 解析,构建 tensorRT 模型并部署等。
本节以 GooLeNet 为例,来展示 tensorRT 的优化方法。
例程位于 /usr/src/tensorrt/samples/sampleGoogleNet
这个例程展示的是 TensorRT的layer-based profiling和 half2mode 和 FP16 使用方法。
1 Key Concepts
首先了解几个概念:
Profiling a network :就是测量网络每一层的运行时间,可以很方便的看出:使用了TensorRT和没使用TensorRT在时间上的差别。
FP16 :FP32 是指 Full Precise Float 32 ,FP 16 就是 float 16。更省内存空间,更节约推理时间。
Half2Mode :tensorRT 的一种执行模式(execution mode ),这种模式下 图片上相邻区域的 tensor 是 以16位 交叉存储的方式 存在的。而且在 batchsize 大于 1的情况下,这种模式的运行速度是最快的。(Half2Mode is an execution mode where internal tensors interleave 16-bits from
adjacent pairs of images, and is the fastest mode of operation for batch sizes greater
than one. )这是计算机组成原理中涉及到存储方式的选择,不是很懂。大概是下图这样的:
以下分别是 2D和3D情况:
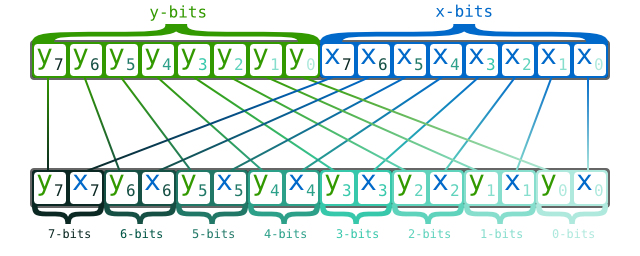
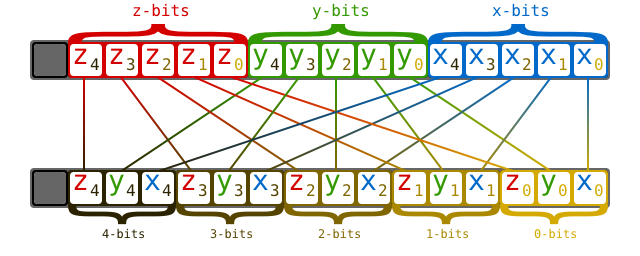
参考这个 顺序存储和交叉存储 ,这样做可以提升存储器带宽。更多详细内容参考文末参考资料。
2 具体做法
2.1 配置 builder
TensorRT3.0的官方文档上说,如果只是使用 float 16 的数据精度代替 float-32 , 实际上并不会有多大的性能提升。真正提升性能的是 half2mode ,也就是上述使用了交叉存存储方式的模式。
如何使用half2mode ?
首先 使用float 16 精度的数据 来初始化 network 对象,主要做法就是 在调用NvCaffeParser 工具解析 caffe模型时,使用 DataType::kHALF 参数,如下:
12345const IBlobNameToTensor *blobNameToTensor =parser->parse(locateFile(deployFile).c_str(),locateFile(modelFile).c_str(),*network,DataType::kHALF);配置builder 使用 half2mode ,这个很简单,就一个语句就完成了:
1builder->setFp16Mode(true);
2.2 Profiling
profiling 一个网络 ,要创建一个 IProfiler 接口并且添加 profiler 到 execution context 中:
|
|
然后执行时,Profiling不支持异步方式,只支持同步方式,因此要使用 tensorRT的同步执行函数 execute() :
|
|
执行过程中,每一层都会调用 profiler 回调函数,存储执行时间。
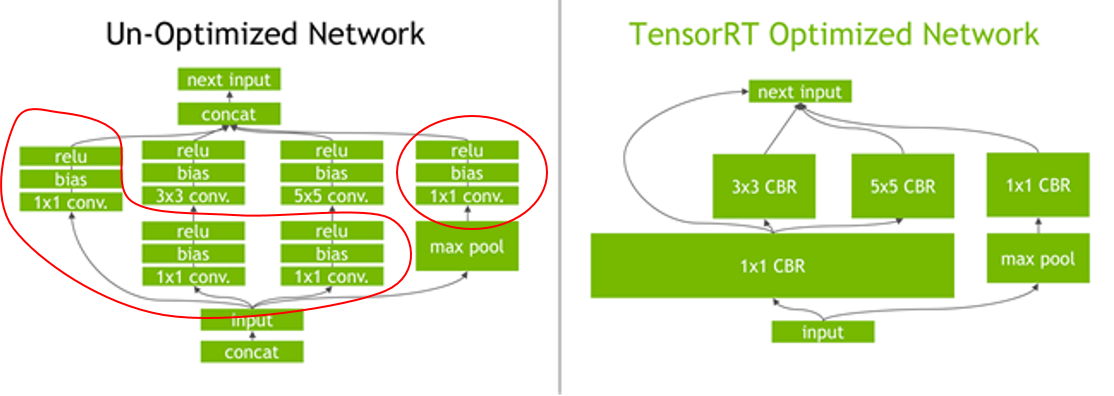
因为TensorRT进行了层间融合和张量融合的优化方式,一些层在 TensorRT 中会被合并,如上图。
比如原来网络中的 inception_5a/3x3 和 inception_5a/ relu_3x3 等这样的层会被合并成 inception_5a/3x3 + inception_5a/relu_3x3 ,因此输出 每一层的时间时,也是按照合并之后的输出。因此TensorRT优化之后的网络结构是跟原来的网络结构不是一一对应的。
3 官方例程
例程位于 /usr/src/tensorrt/samples/sampleGoogleNet
这个例程展示的是 TensorRT的layer-based profiling和 half2mode 和 FP16 使用方法。相比于前面说过的mnist的例程只添加了一些借口和修改了一部分参数,还是贴个完整代码吧,虽然比较占篇幅。
|
|
4 结果分析
TensorRT 的profiling执行结果:
batch=4, iterations=1000, GPU=1080 ti
|
|
这个速度很快的整个网络一次前向过程只有3ms左右。
我们再来看看不用TensorRT的googlenet的profiling结果,这个googlenet使用的是caffe代码中自带的模型文件,profiling用的是caffe 自己的time命令。
将deploy.prototxt 中的batch改为4,迭代次数的话因为这个没有使用TensorRT优化,所以比较费时间,就跑50个iterations,不过也能说明问题了。 同样因为没有使用TensorRT优化,原来的网络结构中是没有进行层间融合的,而且caffe的time命令是把forward和backward都测了时间的,因此输出比较多,所以下面删除了一部分,只保留了inception_5*。
|
|
首先是一次前向的总耗时:
没有使用TensorRT优化的googlenet 是 1046.79ms,使用TensorRT优化的是2.98ms
其次可以看其中的某一层的对比:
inception_5b/1x1 + inception_5b/relu_1x1
优化前:
12inception_5b/1x1 forward: 6.4108 ms.inception_5b/relu_1x1 forward: 0.16204 ms.总耗时:6.57ms
优化后:
1inception_5b/1x1 + inception_5b/relu_1x1 0.075ms总耗时:0.075ms
inception_5b/3x3 + inception_5b/relu_3x3:
优化前:
12inception_5b/3x3 forward: 13.2323 ms.inception_5b/relu_3x3 forward: 0.16636 ms.总耗时:13.40ms
优化后:
1inception_5b/3x3 + inception_5b/relu_3x3 0.046ms总耗时:0.046ms
inception_5b/5x5 + inception_5b/relu_5x5
优化前:
12inception_5b/5x5 forward: 4.08472 ms.inception_5b/relu_5x5 forward: 0.05658 ms.总耗时:4.14ms
优化后:
1inception_5b/5x5 + inception_5b/relu_5x5 0.097ms总耗时:0.079ms
此外还有这些层:
优化前:
12345inception_5b/pool forward: 10.9437 ms.inception_5b/pool_proj forward: 2.21102 ms.inception_5b/relu_pool_proj forward: 0.05634 ms.inception_5b/output forward: 0.26758 ms.pool5/7x7_s1 forward: 2.37076 ms.优化后:
1234inception_5b/pool 0.009msinception_5b/pool_proj + inception_5b/re 0.072msinception_5b/1x1 copy 0.005mspool5/7x7_s1 0.012ms
前面 3×3 卷积比 5×5 卷积还耗时间是因为 3×3 卷积的channel比 5×5 卷积的channel多很多,但是经过TensorRT优化之后二者差别就不是很大了,甚至 5×5 卷积比 3×3 卷积 耗时间。
TensorRT确实极大的降低了前向传播时间,一次前向传播时间只有优化之前的 0.2%,不过这只是分类问题,并且网络也都是传统卷积堆起来的。对于那些复杂结构的网络,比如用于检测的网络或者使用了非经典卷积的比如 dilated conv 或者 deformable conv 的,应该就不会有这么大幅度的提升效果了。不过从英伟达公布的测试数据来看,提升幅度还是蛮大的。
参考
- Morton Coding Overview:http://ashtl.sourceforge.net/morton_overview.html
- Interleaving Explained:http://www.kitz.co.uk/adsl/interleaving.htm
- interleave bits the obvious way:https://stackoverflow.com/questions/3203764/bit-twiddling-hacks-interleave-bits-the-obvious-way
- Bitwise operation:https://en.wikipedia.org/wiki/Bitwise_operation
- 计算机组成原理
- 顺序存储和交叉存储:https://wenku.baidu.com/view/43f5d1d333d4b14e8524687b
- 执行时间计算: https://devtalk.nvidia.com/default/topic/1027443/print-time-unit-is-not-ms-in-samplegooglenet-cpp-of-tensorrt-3-0-sdk-/
- tensorRT API : https://docs.nvidia.com/deeplearning/sdk/tensorrt-api/c_api/classnvinfer1_1_1_i_profiler.html
- tensorRT 用户手册:http://docs.nvidia.com/deeplearning/sdk/tensorrt-developer-guide/index.html#googlenet_sample